

Welcome to a deep dive into the fascinating realm of Natural Language Processing (NLP), a cornerstone of AI that enables computers to interact with human language.
Today, NLP powers everything from voice assistants to customer service chatbots, playing a pivotal role in our tech-driven lives.
In this blog, we will take a closer look at the science behind large language models, the advanced machinery that brings us eerily human-like text.
Have you ever wondered how models like GPT-3 and GPT-4 work?
We’ll peel back the layers to reveal the mechanisms of these impressive models.
From understanding traditional NLP models to exploring the architecture and capabilities of these behemoths, we’ll cover it all.
Introduction to Large Language Model
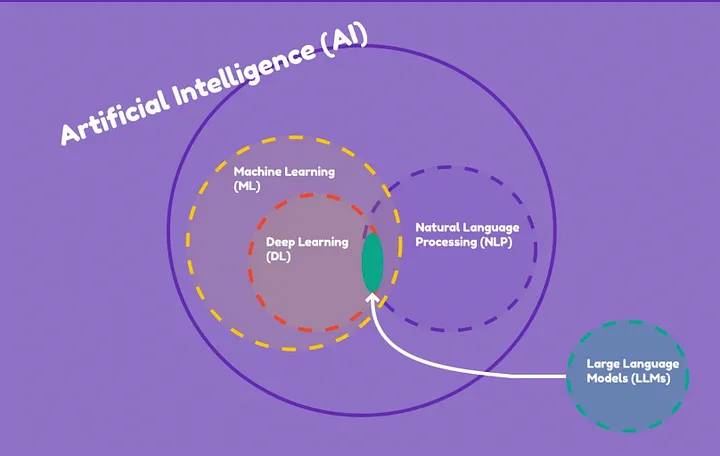
Large language models are machine learning models trained to understand, generate, and interpret text that closely resembles human language.
These models have dramatically changed the landscape of natural language processing, enhancing human-computer interactions. And they are renowned for their scale and complexity, typically boasting hundreds of billions, or even trillions, of parameters.
These parameters, refined through extensive training on expansive text data and powerful computational resources, enable the model to predict subsequent words or phrases in a sequence with striking accuracy.
Prominent examples of such models include OpenAI’s GPT-3 and GPT-4.
GPT-3, with its 175 billion parameters, can write essays, answer questions, and even compose poetry, demonstrating a capability for zero-shot learning, where it makes predictions or generates text without specific task training.
GPT-4, featuring even more parameters, further enhances text generation quality and coherence.
To encapsulate, large language models are revolutionizing natural language processing and artificial intelligence, transforming machine interactions, and enabling a myriad of new applications and services.
Their influence is broad and profound, creating a vibrant landscape ripe with potential.
The Science Behind Large Language Models
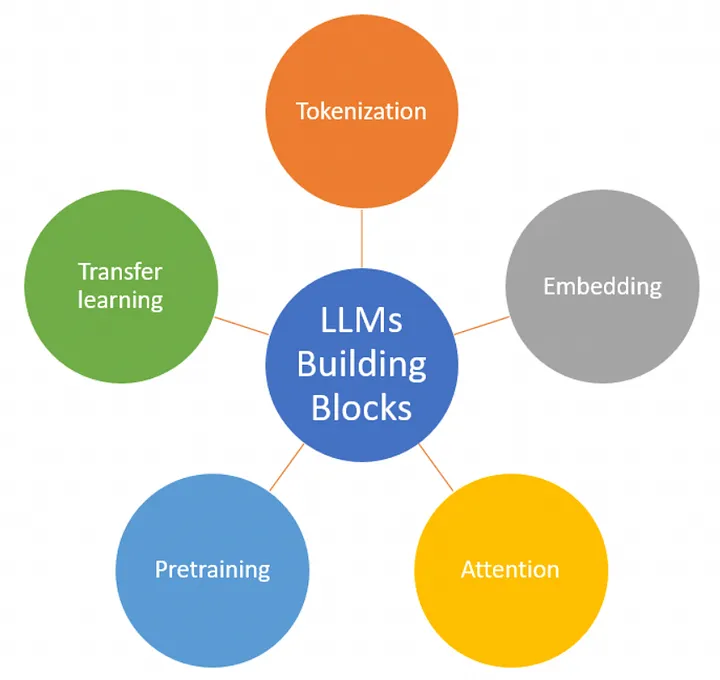
These Large language models, GPT-3 and GPT-4 are powered by a type of neural network architecture known as the Transformer.
Introduced in 2017 in a paper called “Attention is All You Need” by Ashish Vaswani et al., Transformers have become the backbone of most modern large language models due to their superior performance in handling long-range dependencies in text.
The working mechanism of large language models begins with the process of tokenization and embedding.
Tokenization:
Tokenization is the procedure of breaking down a text into smaller parts known as tokens. These tokens are typically words or phrases.
Consider the sentence “The cat is black.”
In the tokenization process, this sentence would be separated into individual tokens: [“The”, “cat”, “is”, “black”].
Embedding:
Embedding is the subsequent process which converts these text tokens into numerical vectors.
A vector in this context is essentially a list or array of numbers, a mathematical object that exists in multidimensional space and can represent a multitude of features.
To make this more tangible, let’s consider an overly simplified example where our language model maps tokens into 2-dimensional vectors for the sake of visual clarity.
The word “cat” could be represented as a point in this space with the coordinates (1.2, 0.7). Likewise, the word “black” could be represented as a different point with the coordinates (0.9, 1.5).
Hence, after the embedding process, the tokens from our initial sentence “The cat is black” could be represented by a set of vectors:
“The” as (0.6, 0.3), “cat” as (1.2, 0.7), “is” as (0.8, 0.4), and “black” as (0.9, 1.5).
This process provides the language model with a mathematical understanding of the words, thereby enabling it to analyze and manipulate the language data.
After the process of tokenization and embedding, we enter the next crucial stage of the Transformer architecture: the self-attention mechanism and positional encoding.
These two mechanisms work in tandem to help the model understand the relationships between words and their positions within a sentence.
The Self-Attention mechanism
The self-attention mechanism in the Transformer model allows it to consider the entire text input when generating an output for a specific word. It determines the importance of each word in relation to every other word in the sentence.
For instance, in the sentence “The cat, which is black, is on the mat,” the self-attention mechanism would allow the model to link the word “black” to “cat”, despite the words in between.
However, Transformers process all tokens simultaneously and thus lack a built-in understanding of the positional order of words.
This is where positional encoding comes in.
Positional encoding:
Positional encoding is added to give the model a sense of the order of the words.
It is a vector of numbers, just like the embedding, but instead of representing the meaning of a word, it represents the position of a word in the sentence.
For example, in the sentence “The cat is black”, the positional encoding would provide unique vectors representing positions 1, 2, and 3 for the words “The”, “cat”, and “is”, respectively. This helps the model understand that “The” comes before “cat”, and “cat” comes before “is”.
This is crucial for languages like English where the order of words can dramatically change the meaning of a sentence.
Thus, the Transformer uses tokenization, embedding, self-attention, and positional encoding to process language data and generate text that can mimic the coherence and contextuality of human-written text.
Training large language models:
Training large language models is indeed a resource-intensive process, involving vast amounts of data, significant computational power, and extensive periods of time.
These models are trained on massive and diverse datasets, sometimes encompassing trillions of words from the internet, books, articles, and more.
But what does it mean to “train” these models?
At the heart of these models lie parameters.
In the context of machine learning models, parameters are internal variables that the model uses to make predictions. They can be thought of as the knobs that the model adjusts during training to improve its predictions.
For instance, in our earlier example with word embeddings, each number in the vector that represents a word is a parameter.
The main objective during training is to fine-tune these parameters in such a way that the model gets better at its task.
For language models, the task is usually to predict the next word in a sentence given the previous words.
For example, consider the sentence “The cat is ___.”
After training, a well-tuned language model should be able to accurately predict that words like “black”, “small”, or “playful” are probable next words, while “moon”, “sky”, or “building” are less likely.
However, the sheer number of parameters (sometimes in the order of billions or even trillions) and the colossal volume of data used for training translate to a massive computational challenge.
This task could require hundreds of powerful GPUs running in parallel for several weeks, or even months.
Despite these challenges, the benefits are clear:
A well-trained language model can generate human-like text, answer questions, write code, and much more, thus expanding the horizons of what is achievable with AI.
The Power and Limitations of Large Language Model
The advent of large language models, such as GPT-3 and GPT-4, has greatly amplified the capabilities of AI in terms of natural language understanding and generation.
These models have found application in drafting emails, coding, content creation, translation, tutoring, and even in crafting poetry and prose, representing a broad spectrum of uses.
A significant case study that showcases the power of these models is OpenAI’s ChatGPT.
It simulates human-like text conversations and has been successfully used in customer service for handling queries, in education for tutoring, and in gaming to generate character dialogues.
ChatGPT’s capacity to produce coherent, contextually relevant responses underscores the transformative potential of large language models.
Despite their notable capabilities, these models are not without limitations and challenges.
Their performance is contingent on the quality and diversity of their training data. Any inherent bias in this data can be reflected and amplified by the models.
Additionally, they might generate inappropriate or nonsensical responses when faced with unfamiliar or out-of-context inputs.
A notable limitation is their lack of genuine understanding.
Despite their skill in language manipulation, these models don’t truly comprehend text in the way humans do. They lack the ability to reason and make judgments about real-world situations; their output is purely based on the training they’ve received.
Furthermore, the use of large language models also raises important ethical considerations. The potential for misuse, such as generating misleading information or offensive language, is significant and necessitates the implementation of robust guidelines and safeguards.
Conclusion
As we navigate the exciting terrain of Natural Language Processing (NLP) and large language models, we find ourselves on the brink of an AI revolution.
Techniques like zero-shot and transfer learning promise great advancements, while the focus on efficiency, interpretability, and ethics presents challenges to be addressed.
In this rapidly evolving landscape, staying informed is crucial.
As a reader, whether you’re a researcher, developer, or AI enthusiast, your engagement matters.
Your role is invaluable in this journey, and I am very excited to see what the future holds.